Description
Dataflow kit is a Scraping framework for Gophers. DFK extracts structured data from web pages, following the specified extractors.
It can be used in many ways for data mining, data processing or archiving.
Dataflow kit alternatives and similar packages
Based on the "Text Processing" category.
Alternatively, view Dataflow kit alternatives based on common mentions on social networks and blogs.
-
-
goldmark
:trophy: A markdown parser written in Go. Easy to extend, standard(CommonMark) compliant, well structured. -
bluemonday
bluemonday: a fast golang HTML sanitizer (inspired by the OWASP Java HTML Sanitizer) to scrub user generated content of XSS -
-
html-to-markdown
⚙️ Convert HTML to Markdown. Even works with entire websites and can be extended through rules. -
-
mxj
Decode / encode XML to/from map[string]interface{} (or JSON); extract values with dot-notation paths and wildcards. Replaces x2j and j2x packages. -
-
omniparser
omniparser: a native Golang ETL streaming parser and transform library for CSV, JSON, XML, EDI, text, etc. -
-
go-pkg-rss
This package reads RSS and Atom feeds and provides a caching mechanism that adheres to the feed specs. -
go-edlib
📚 String comparison and edit distance algorithms library, featuring : Levenshtein, LCS, Hamming, Damerau levenshtein (OSA and Adjacent transpositions algorithms), Jaro-Winkler, Cosine, etc... -
goq
A declarative struct-tag-based HTML unmarshaling or scraping package for Go built on top of the goquery library -
github_flavored_markdown
GitHub Flavored Markdown renderer with fenced code block highlighting, clickable header anchor links. -
go-pkg-xmlx
Extension to the standard Go XML package. Maintains a node tree that allows forward/backwards browsing and exposes some simple single/multi-node search functions. -
-
-
-
-
pagser
Pagser is a simple, extensible, configurable parse and deserialize html page to struct based on goquery and struct tags for golang crawler

WorkOS - The modern identity platform for B2B SaaS










Do you think we are missing an alternative of Dataflow kit or a related project?

|
InfluxDB - Power Real-Time Data Analytics at Scale
sponsored
www.influxdata.com
|
Popular Comparisons

|
SaaSHub - Software Alternatives and Reviews
sponsored
www.saashub.com
|
README
Dataflow kit
![]()


![]()
Dataflow kit ("DFK") is a Web Scraping framework for Gophers. It extracts data from web pages, following the specified CSS Selectors.
You can use it in many ways for data mining, data processing or archiving.
The Web Scraping Pipeline
Web-scraping pipeline consists of 3 general components:
- Downloading an HTML web-page. (Fetch Service)
- Parsing an HTML page and retrieving data we're interested in (Parse Service)
- Encoding parsed data to CSV, MS Excel, JSON, JSON Lines or XML format.
Fetch service
fetch.d server is intended for html web pages content download. Depending on Fetcher type, web page content is downloaded using either Base Fetcher or Chrome fetcher.
Base fetcher uses standard golang http client to fetch pages as is. It works faster than Chrome fetcher. But Base fetcher cannot render dynamic javascript driven web pages.
Chrome fetcher is intended for rendering dynamic javascript based content. It sends requests to Chrome running in headless mode.
A fetched web page is passed to parse.d service.
Parse service
parse.d is the service that extracts data from downloaded web page following the rules listed in configuration JSON file. Extracted data is returned in CSV, MS Excel, JSON or XML format.
Note: Sometimes Parse service cannot extract data from some pages retrieved by default Base fetcher. Empty results may be returned while parsing Java Script generated pages. Parse service then attempts to force Chrome fetcher to render the same dynamic javascript driven content automatically. Have a look at https://scrape.dataflowkit.com/persons/page-0 which is a sample of JavaScript driven web page.
Dataflow kit benefits:
- Scraping of JavaScript generated pages;
- Data extraction from paginated websites;
- Processing infinite scrolled pages.
- Sсraping of websites behind login form;
- Cookies and sessions handling;
- Following links and detailed pages processing;
- Managing delays between requests per domain;
- Following robots.txt directives;
- Saving intermediate data in Diskv or Mongodb. Storage interface is flexible enough to add more storage types easily;
Encode results to CSV, MS Excel, JSON(Lines), XML formats;
Dataflow kit is fast. It takes about 4-6 seconds to fetch and then parse 50 pages.
Dataflow kit is suitable to process quite large volumes of data. Our tests show the time needed to parse appr. 4 millions of pages is about 7 hours.
Installation
go get -u github.com/slotix/dataflowkit
Usage
Docker
Install Docker and Docker Compose
Start services.
cd $GOPATH/src/github.com/slotix/dataflowkit && docker-compose up
This command fetches docker images automatically and starts services.
- Launch parsing in the second terminal window by sending POST request to parse daemon. Some json configuration files for testing are available in /examples folder.
curl -XPOST 127.0.0.1:8001/parse --data-binary "@$GOPATH/src/github.com/slotix/dataflowkit/examples/books.toscrape.com.json"Here is the sample json configuration file:
{
"name":"collection",
"request":{
"url":"https://example.com"
},
"fields":[
{
"name":"Title",
"selector":".product-container a",
"extractor":{
"types":["text", "href"],
"filters":[
"trim",
"lowerCase"
],
"params":{
"includeIfEmpty":false
}
}
},
{
"name":"Image",
"selector":"#product-container img",
"extractor":{
"types":["alt","src","width","height"],
"filters":[
"trim",
"upperCase"
]
}
},
{
"name":"Buyinfo",
"selector":".buy-info",
"extractor":{
"types":["text"],
"params":{
"includeIfEmpty":false
}
}
}
],
"paginator":{
"selector":".next",
"attr":"href",
"maxPages":3
},
"format":"json",
"fetcherType":"chrome",
"paginateResults":false
}
Read more information about scraper configuration JSON files at our GoDoc reference
Extractors and filters are described at https://godoc.org/github.com/slotix/dataflowkit/extract
- To stop services just press Ctrl+C and run
cd $GOPATH/src/github.com/slotix/dataflowkit && docker-compose down --remove-orphans --volumes
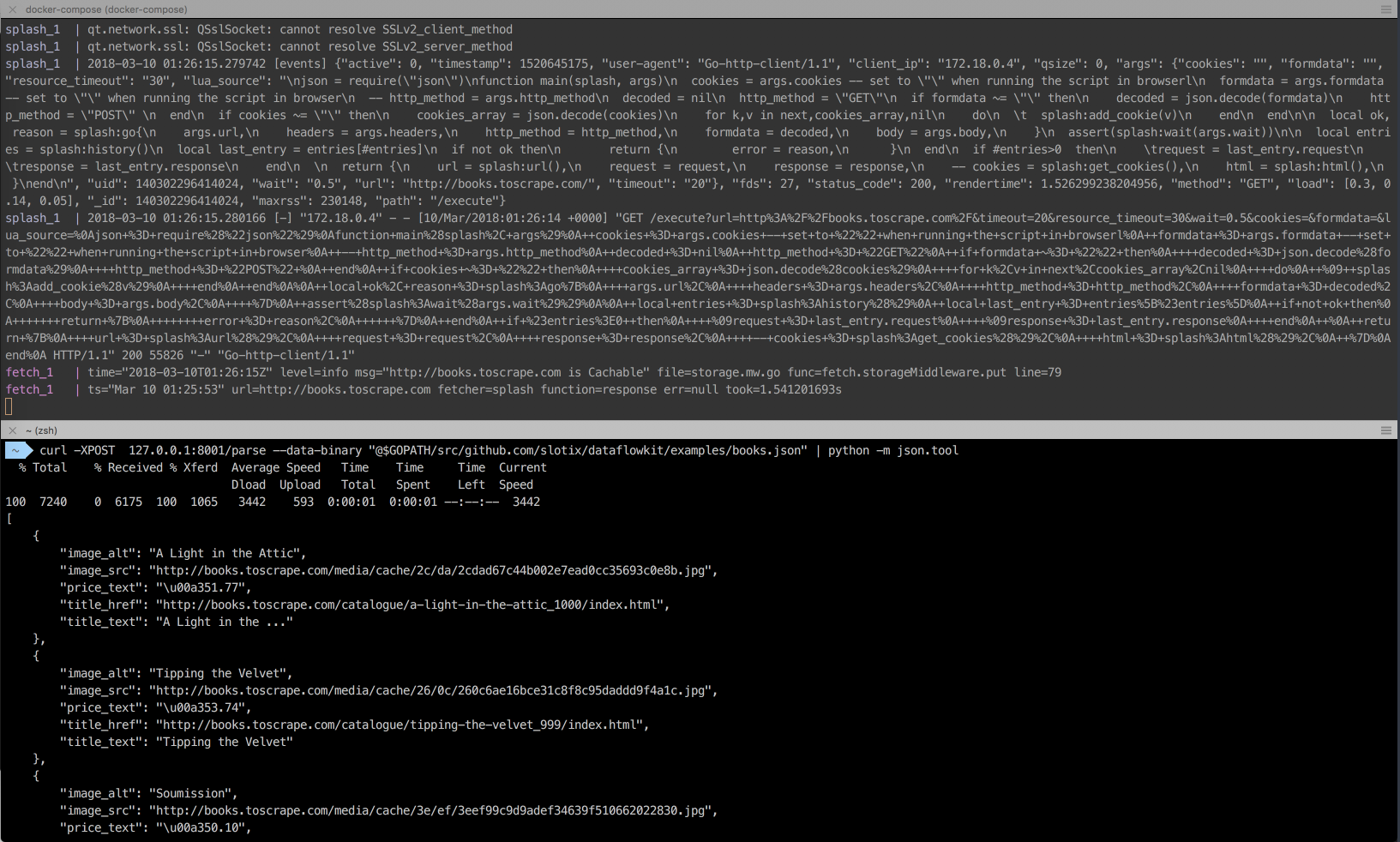
Click on image to see CLI in action.
Manual way
- Start Chrome docker container
docker run --init -it --rm -d --name chrome --shm-size=1024m -p=127.0.0.1:9222:9222 --cap-add=SYS_ADMIN \ yukinying/chrome-headless-browser
Headless Chrome is used for fetching web pages to feed a Dataflow kit parser.
- Build and run fetch.d service
cd $GOPATH/src/github.com/slotix/dataflowkit/cmd/fetch.d && go build && ./fetch.d - In new terminal window build and run parse.d service
cd $GOPATH/src/github.com/slotix/dataflowkit/cmd/parse.d && go build && ./parse.d - Launch parsing. See step 3. from the previous section.
Run tests
docker-compose -f test-docker-compose.yml up -d./test.sh- To stop services just run
docker-compose -f test-docker-compose.yml down
Front-End
Try https://dataflowkit.com/dfk Front-end with Point-and-click interface to Dataflow kit services. It generates JSON config file and sends POST request to DFK Parser
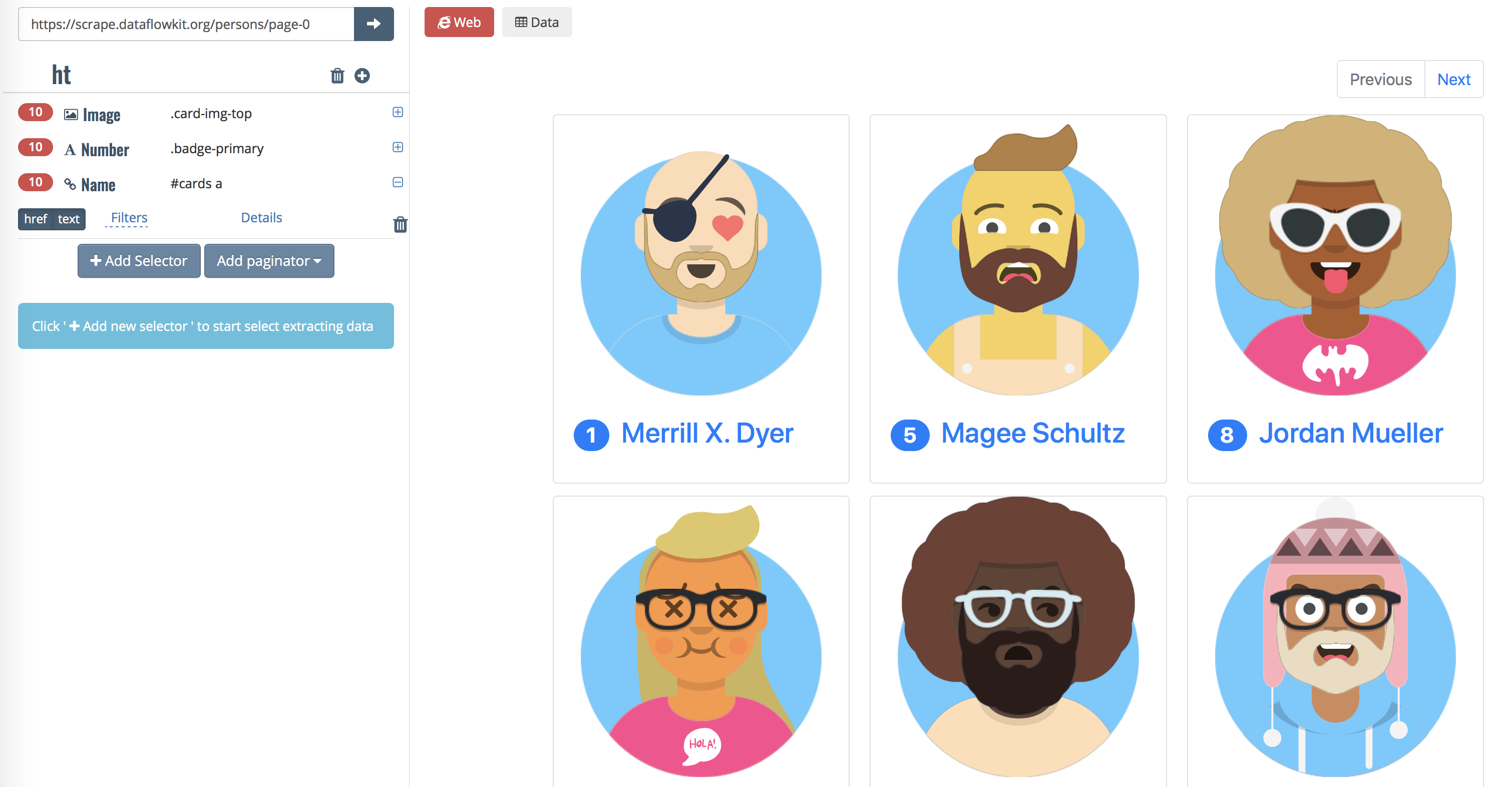
Click on image to see Dataflow kit in action.
License
This is Free Software, released under the BSD 3-Clause License.
Contributing
You are welcome to contribute to our project.
- Please submit your issues
- Fork the project
*Note that all licence references and agreements mentioned in the Dataflow kit README section above
are relevant to that project's source code only.